
Contents
Introduction to /robots.txt
The /robots.txt standard allows website owners to give instructions to robots that visit their websites. This can be a request to not crawl a certain part of a website or an instruction where to find the XML sitemap.
The /robots.txt is a plain-text file with simple instructions always placed on the same location of a website:
How does it work?
A robots from for example Google checks if a website has a /robots.txt file before it first crawls a website. It looks for rules specific for their User-agent (Googlebot). If none are found it follows the generic User-agent rules.
Valid /robots.txt rules
User-agent:
Every robot has it’s own user-agent. This is essentially a name for the robot allowing you to give certain bots access to files and others not.
User-agent: *= Any robotUser-agent: Google= Google searchUser-agent: Googlebot-Image= Google imagesUser-agent: AhrefsBot= Ahrefs webcrawler
Important: A robot will only pay attention to the most specific group of instructions. In the example below there are two User-agent instructions. One for “any robot” and one for “DuckDuckBot”. The DuckDuckBot will only look at it’s own instructions (and ignore the other rules) and will look in the other folders like /api/.
User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /api/ User-agent: DuckDuckBot Disallow: /duckhunt/
Disallow:
With the Disallow rule you can easily block entire sections of your website from being indexed in search engines. You can also block access to the entire site for all or specific bots. Depending on your needs this can be useful with dynamic, temporary or login secured sections of your site.
User-agent: * # Block /cms and any files in it Disallow: /cms # Block /images/resized (/images is still allowed) Disallow: /images/resized/
To make this easier you can use pattern-matching to block complex URLs.
*= any sequence of characters$= Match the end of an URL
User-agent: * # Block URLs starting with /photo like # /photos # /photo/overview Disallow: /photo # Block URLs starting with /blog/ and ending with /stats/ Disallow: /blog/*/stats$
(The hash symbol is a way to add comments. Robots will ignore these.)
Important: Don’t block your CSS or JavaScript files. Search engines need this to properly render your website.
Allow:
With the Allow rule you can unblock a subdirectory that is being blocked by a disallow rule. This can be useful if you’ve Disallowed part (or the entire) site but want to allow specific files/folders.
User-agent: * # Block access to everything in the admin folder Disallow: /admin # Except /admin/css/style.css Allow: /admin/css/style.css # And everything in the /admin/js folder. Like: # /admin/js/global.js # /admin/js/ajax/update.js Allow: /admin/js/
Another use is giving access to specific robots.
# Deny access to all robots User-agent: * Disallow: / # Except Googlebot User-agent: Googlebot Allow: /
Crawl-delay:
If a robot is using too much resources on the website you can slow down their crawling with the Crawl-delay rule.
User-agent: * Crawl-delay: 5
Since this is not an official part of the standard the implementation changes depending on the robot. In general: the higher the number the less times your site will get crawled.
- Google (Googlebot) ignores this command. You can modify crawl speed in the Search Console.
- Baidu ignores this command. It it’s possible to modify using their Webmaster Tools feature but this is currently not available in English.
- Bing (BingBot) treats this is a ‘time-window’ during which BingBot will crawl your web site only once.
- Yandex (YandexBot) number of seconds to wait between crawls.
Important: If a Robots.txt contains a high Crawl-delay check to make sure your site is being indexed timely. Since there are 86400 seconds in a day a Crawl-Delay: 30 is 2880 pages crawled per day which might be too few for big sites.
Sitemap:
One of the main uses of a /robots.txt file (for SEOs) is declaring the sitemap(s). This is done by adding the following line followed by the full URL.
Sitemap: https://www.example.com/sitemap.xml Sitemap: https://www.example.com/blog-sitemap.xml
If you have multiple sitemaps you can add them with a new rule.
Things to keep in mind
- Sitemap needs to start with a capital S.
- Sitemap is independent of user-agent instructions.
- The link needs to be a full URL. You can’t use a relative path.
Make sure the link returns a HTTP 200 OK header (no redirects).
Common /robots.txt
These are some common /robots.txt templates you can use for your websites.
Allow full access
Don’t block any robot for accessing your website by leaving an empty Disallow rule.
User-agent: * Disallow:
Block all access
User-agent: * Disallow: /
Disallow a certain folder
User-agent: * Disallow: /admin/
Disallow a certain file
User-agent: * Disallow: /images/my-embarrassing-photo.png
Add a sitemap
Sitemap: https://www.example.com/sitemap.xml
Common mistakes
Setting custom User-agent rules without repeating Disallow rules
Due to the way /robots.txt work if you set a custom User-agent for a bot it will only follow the rules you set for it. A commonly made mistake is to have advanced Disallow rules for the wildcard (`*`) and later adding a new rule without repeating these Disallow rules.
# (Redacted version of IMDb /robots.txt) # # Limit ScoutJet's crawl rate # User-agent: ScoutJet Crawl-delay: 3 # # # # Everyone else # User-agent: * Disallow: /tvschedule Disallow: /ActorSearch Disallow: /ActressSearch Disallow: /AddRecommendation Disallow: /ads/ Disallow: /AlternateVersions Disallow: /AName Disallow: /Awards Disallow: /BAgent Disallow: /Ballot/ # # Sitemap: http://www.imdb.com/sitemap_US_index.xml.gz
The /robots.txt for IMDb has extensive Disallow rules but these are not repeated for ScoutJet. Giving that bot access to all folders.
Common User-agent’s
Looking for a specific robot? These are the most commonly used /robots.txt User-agents.
| User-agent | # |
|---|---|
| Google [more details] | |
| Googlebot | Regular Google search bot |
| Googlebot-Image | Google Images robot |
| Bing [more details] | |
| Bingbot | Regular Bing search bot |
| MSNBot | Old crawler for Bing but still in use |
| MSNBot-Media | Crawler for Bing Images |
| BingPreview | Page Snapshot creator [more details] |
| Yandex [more details] | |
| YandexBot | Regular Yandex search bot |
| YandexImages | Crawler for Yandex Images |
| Baidu [more details] | |
| Baiduspider | Main search spider for Baidu |
| Baiduspider-image | Crawler for Baidu Images |
| Applebot | Crawler for Apple. Used for Siri and Spotlight Suggestions. |
| SEO Tools | |
| AhrefsBot | Webcrawler for Ahrefs |
| MJ12Bot | Webcrawler for Majestic |
| rogerbot | Webcrawler for Moz |
| Misc | |
| DuckDuckBot | Webcrawler for DuckDuckGo |
Advanced Wildcard tricks
There are two wildcards widely supported. The asterisks * to match any sequence of characters and the $ which matches the end of an URL.
Block specific filetypes
User-agent: * # Block files ending in .json # The asterisks allows any file name # The dollar sign ensures it only matches the end of an URL and not a oddly formatted url (e.g. /locations.json.html) Disallow: /*.json$
Block any URL with a ?
User-agent: * # Block all URLs that contain a question mark Disallow: /*?
Block search result pages (but not the search page itself)
User-agent: * # Block search results page Disallow: /search.php?query=*
FAQs about /robots.txt
Do I really need a /robots.txt file?
Yes. While you can get by without a /robots.txt file it’s smart to always create one. Good bots will always try to visit your /robots.txt file. If you don’t have one your server logs will fill up with 404 errors. If you want you can simply create an empty file.
My /robots.txt doesn’t have a Sitemap, should I add one?
Yes. While you definitely should submit your sitemap via Google Search Console it’s a smart idea to also add it to your robots.txt. It’s simple to do and saves you from submitting your sitemap to all search engines (Google, Bing, Yandex, Baidu all have their own webmaster tools). It also helps other (non search engine) crawlers from finding your sitemap.
Are directories case-sensitive?
Like most URLs, Disallow and Allow rules are case-sensitive. Make sure your rules are the same case as your URLs.
User-agent: * # /users will still be crawled since the case doesn't match Disallow: /Users
Are field / instructions case-sensitive?
The instructions themselves are not case sensitive. You can specify a rule as Disallow: or disallow:.
How can I test changes to /robots.txt files?
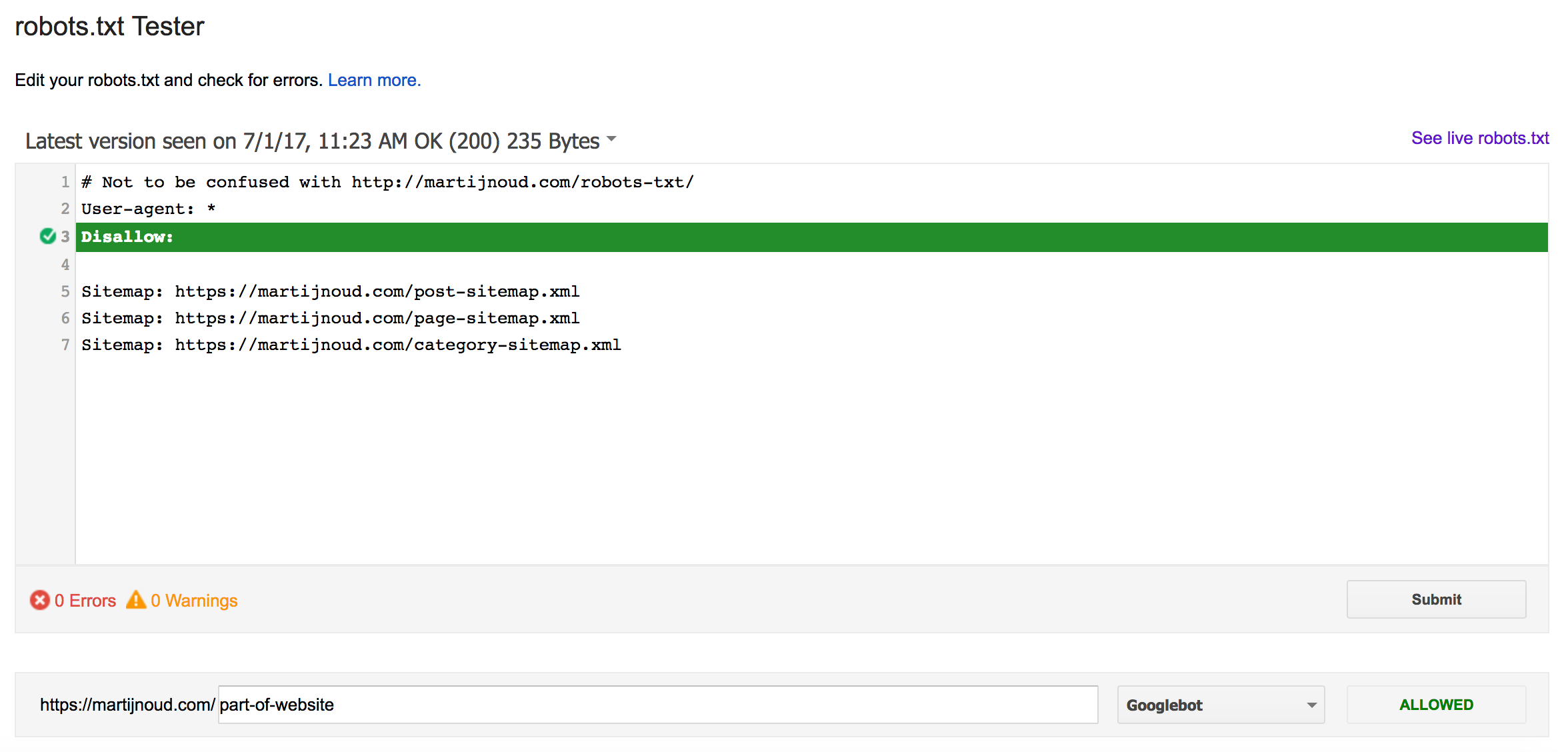
There are some free /robots.txt parsers online but the most reliable way is via Google Search Console. This contains an advanced tool where you can enter an URL and check if Google is allowed to crawl it.
This blog doesn't have a comment section. That doesn't mean I don't want your feedback but I'd rather have a more personal conversation via Email or Twitter.