To test if Google does any Optical Character Recognition (OCR) on images found on websites and uses that information in it’s index I wanted to run a small experiment. So I published an article with new images contain some simple text and waited to see if the page would rank for the words on the images.
The Test
To generate a topic I used the Random Article button on Wikipedia. After a couple of tries I landed on the interesting story of Vladimir Komarov. A Russian cosmonaut whose lively tragically came to and during a mission making him the first man to die in a space flight.
To test if my article would rank for the words I mashed some keywords together to create unique, gibberish, words. I overlayed these words on cropped images creating images varying levels of difficulty.
To make sure Google’s software could actually read my images I tested it with the OCR feature on Google Documents. I uploaded an image to Google Drive and selected Open With -> Google Documents. This creates a new document with the image and the extracted text. Yes, Google could accurately read my unique images!

I created a new WordPress blog, wrote an article about Komarov, included my images without any alt or title tags to encourage Google to look further and waited about two weeks…
The Result
Does Google do OCR on images on the web? No. At least, not as of now.
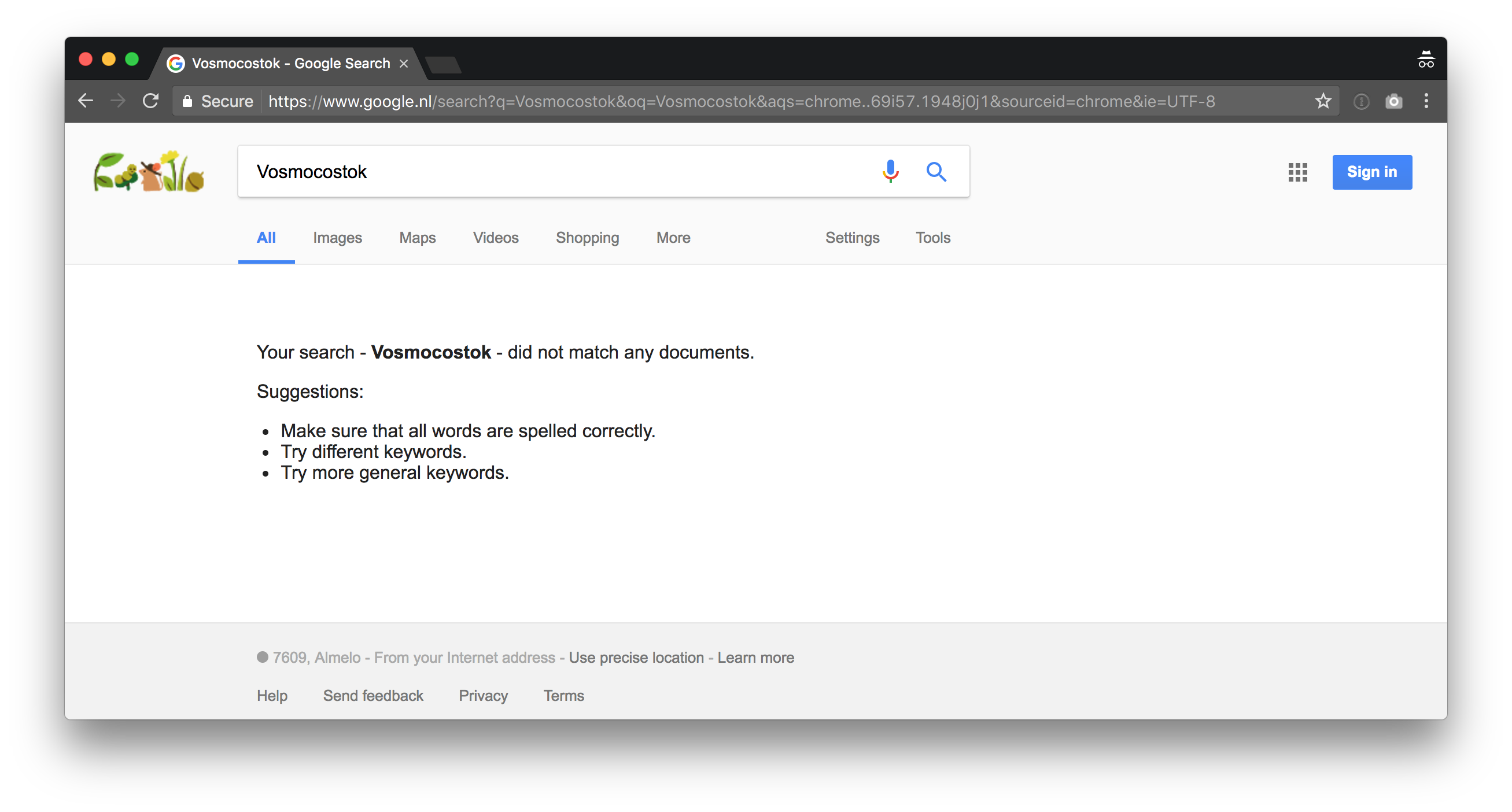
The article about Komarov was indexed in Google but my gibberish words never showed up in Google. The technology is certainly there but due to the sheer size of the web (hundreds of billions of pages) it’s likely too resource intensive.
What can you learn from this?
Optimize images for search engines is still fairly straight forward. You need good alt- and title text, descriptive filenames and if possible a caption. You don’t yet have to worry about more advanced strategies but I do expect this will change in the future.
This blog doesn't have a comment section. That doesn't mean I don't want your feedback but I'd rather have a more personal conversation via Email or Twitter.